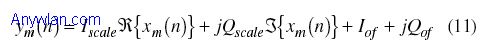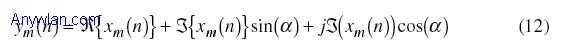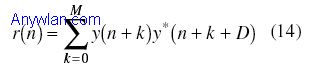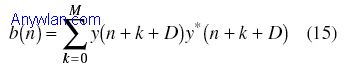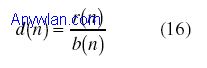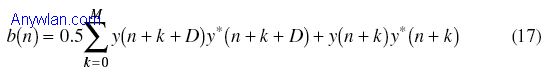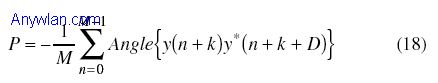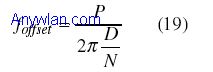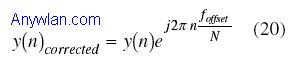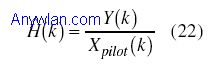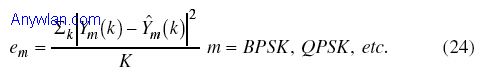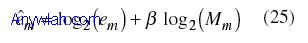|
使用WiMAX高数据速率技术的无线应用将在今后几年内有很大发展。基于正交频分复用(OFDM)技术,WiMAX保持着对作为多媒体业务网络“最后一英里”一部分的宽带无线接入(BWA)的承诺。 本网站的技术文章《WiMAX收发机的工作原理和测试流程》中,对WiMAX物理层(PHY)和媒质接入控制(MAC)协议展开了讨论,这些是IEEE 802.16-2004标准要点以及WiMAX基带收发信机的基本特征。本文将讨论如何设计基带WiMAX接收机,并讨论它的各种测量算法。 《WiMAX收发机的工作原理和测试流程》讨论了WiMAX基带接收机模型的各种要素,包括同相/正交(I/Q)增益不匹配、正交误差。在基带发射机和信道模型中,I/Q初始偏移和I/Q增益不匹配被引入到时域信号:
当Iscale = Qscale时,I/Q不匹配为零。当Iof和Qof均为零时,没有I/Q偏移。图7给出了接收符号星座图中IQ增益不匹配的情形。 正交倾斜误差显示I和Q信号间的正交误差。理想情况下,I和Q信道应该精确正交(相隔90度),当正交性不理想时(小于或大于90度或±90度),就可观察到正交误差。在基带信号模型中,Q偏移对时域信号的影响为:
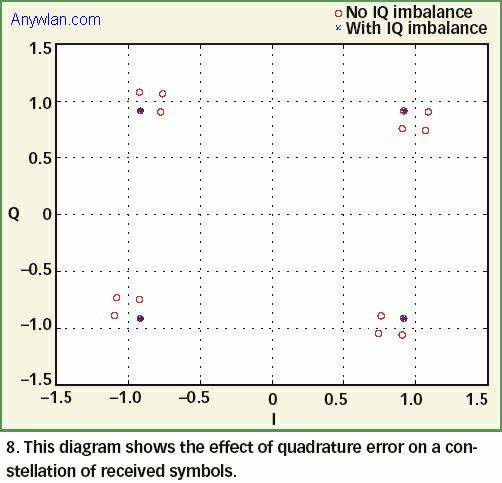
其中,α是正交误差。 当α等于0度时,ym(n)等于Xm(n)(没有正交误差)。图8给出了接收符号星座图中正交误差的影响。
接收信号可建模(I/Q完全一致情况下)为:
其中, Φmcommom是由剩余频偏引起(进行频偏补偿后)公共相位误差以及先前描述的其它可能误差源; Φm(k)carrier dep是依赖载波的相位旋转,主要由采样定时偏移引起; Γm是公共增益偏移,可以由放大器增益变化造成。 所有其它噪声或者折合成AWGN项zm(k)(如果噪声是加性的),或者折合成信道频率响应(如果噪声是乘性的)。 图9给出了所提出WiMAX测试接收机的框图。该接收机设计用于测试和测量,因此同用于WiMAX产品的实际接收机算法有一些区别。还要注意到的是这种接收机为数字基带接收机,处理由任意接收机或者矢量信号分析仪的模拟前端给出的I/Q数据。接收信号还要经过信道模拟器以加入前面提到的所需的损害(用于测试目的)。这样,接收信号就代表了包括因实际硬件(在发射机和接收机前端)造成的可能损害在内的I/Q样本以及包括在信道模拟器内的内部损害。
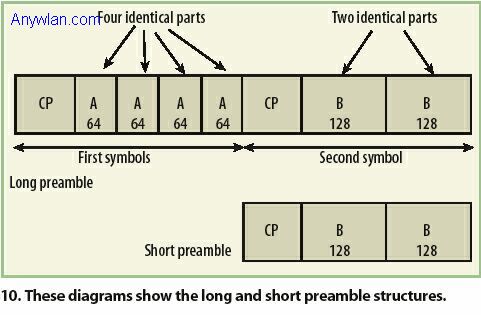
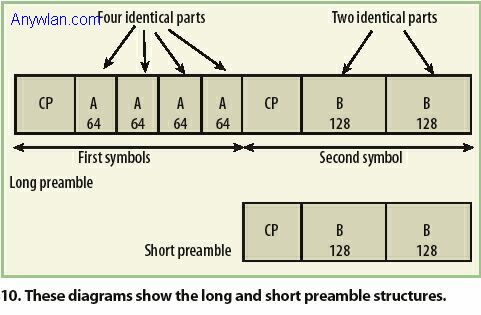
发射机可以是传输标准WiMAX信号的任何信号源,它可以是一台矢量信号发射器(VSG)或者仿真器。笔者用MATLAB软件开发了一种基于标准的数字基带发射机用于测试单机模式下的WiMAX性能。仿真的发射机具有类似信道编码、产生所有可能调制(BPSK、QPSK、16QAM、64QAM)、编码选择(turbo码除外)、所有可能循环前导选择、上下行图发生成、所有可能采样率以及带宽选择、灵活的突发符号数量选择以及生成随机与标准测试数据等功能。不过,正如前面所述,没有什么必要去使用发射机仿真器,因为主要目的是用所提出接收机去测试第三方发射机产品。然而,仍然值得使用仿真发射机产生的合成数据用于调试和交叉检查。不管用哪种发射机,只要是基于IEEE 802.16-2004标准的发射机,所提议接收机就可以设计来合理工作。全部功能模块对于测试和测量发射机质量都是必要的,这些功能模块如图9所示。 ###NextPage### 用MATLAB模拟的基带接收机可进行许多操作:寻找RF突发和突发的分组界限、估计和校正粗频偏、估计与进行粗和细微符号时间同步;估计分组(RF 突发)结束位置以及准确有用的分组信息;实现精细频偏估计和残留频偏校正;去除CP和转换时域信号为频域符号;估计信道频率响应(CFR)和纠正因公共相位偏移以及载波依赖性相位偏移带来的符号旋转;利用CFR进行频域均衡;检测符号和得到为信道译码器所用的软符号值;应用去交织器/解码器/去随机化器;对FCH域解码和CRC校验。在随后部分将对每个模块进行简要解释。注意到其中一些模块是类似于去交织/解码/去随机性、FFT、CP消除等的标准信号处理模块,关于这些模块的信息随处可得,这里就不再做进一步解释。 注意到在WiMAX(类似其它无线通信系统)中,训练序列被插入在数据符号之内以帮助同步和信道估计。下行链路子帧始于两个在用户站用于同步和信道估计的OFDM符号,这两个符号一起表示了下行链路(DL)子帧的前导头并被叫做“长前导”。上行链路子帧始于一个OFDM符号,该符号被基站用来与独立的SS达到同步。该单个上行链路符号被叫做“短前导”。 图10给出了长短前导的结构。长前导的第一个符号由每个第四路载波(200路载波中共有50路)组成,这样,时域信号就有四个重复部分。虽然长前导的第一个符号对粗信号采集有用,它对于精确的信道测量和校正还不够,因此在下行链路子帧中,第一个符号之后紧接着另一个同样长度的符号,该符号包括交替的运行载波。在时域中,第二个符号有两个重复部分。
运用分组检测技术来确定是否有有用分组存在(并用来发现分组的起始点)。训练序列的重复性结构被用于这种搜索,搜索使用了两个滑动窗。第一个窗用来计算接收信号及其延迟信号之间的自相关。延迟量等于重复序列的长度,这取决于是下行链路还是上行链路。第二个窗口被用来获得接收信号的功率以便对判决统计量进行归一化,这样判决变量就不再依赖于瞬时功率。两个窗口的长度为相同值M,第一个和第二个窗口值可表示为:
判决变量为:
这里,y(n)是接收信号,M是窗口长度。 如果d(n)的幅度超过了门限,就可以假定在d(n)超过门限处的起始点有一个输入分组。门限选择是设计关键,需要在虚警率和漏报率之间进行折衷。 作者对上面的方法引入了附加修正,包括在下行链路(D=128)和上行链路(D=64)使用不同的D。自适应门限(始于高门限并逐渐降低该值)。此外,为了计算b(n),作者认识到最好采取如下的办法:
图11给出了分组检测算法的样本输出,它显示自相关和滑动平均滤波之后的结果。输出样本对应不同门限。只要某点到达样点超过门限的位置,那就宣告为一个分组,该点也就被认定是分组的起始点。图11是在很好的SNR值(SNR = 80 dB)情况下获得的,噪声相关性接近于0,反复部分的相关性接近于1。对于低信噪比值,峰值将下降。还应注意相关器在峰值附近的输出并不像冲激(或者窄脉冲),而是一相当宽的脉冲。因此,分组检测的输出仅提供了寻找分组起始位置的粗略办法。
###NextPage###使用训练序列估计出频偏,这类方法如参考文献13给出的Moose法。训练序列的两个相同部分间的平均相位差被计算出来并归一化以得到频偏。平均相位差可按下式计算:
接下来平均相位值被用于计算频偏:
在下行链路中,对于粗频偏估计,两个长度为64的数据块被使用在第一个符号(M=D=64)的中间,这样做有两个好处:1)通过只使用长度为64的更短数据块,可以补偿较大的频偏;2)使用中间数据块,误差对频偏估计粗定时的影响可以降低。在上行链路中,除了使用短前导(这里M = D = 128),我们别无选择。 对于精细频偏估计(上行和下行链路),第二符号被用在使用长度为128的数据块可以得到更佳噪声平均的地方。在上行链路中,除了使用这个符号,没有其它选择。 一旦计算出频偏,接收到的时间样本值就可以按估计频偏的反方向旋转以补偿频偏的影响,即:
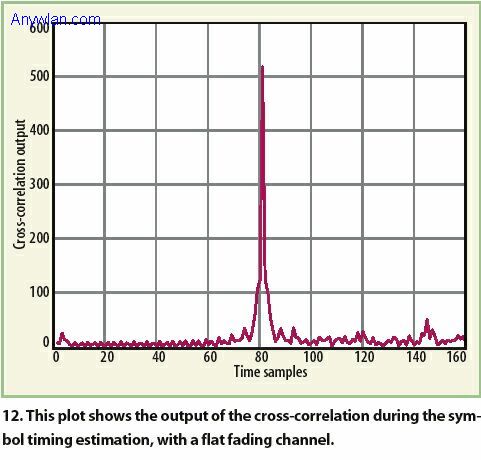
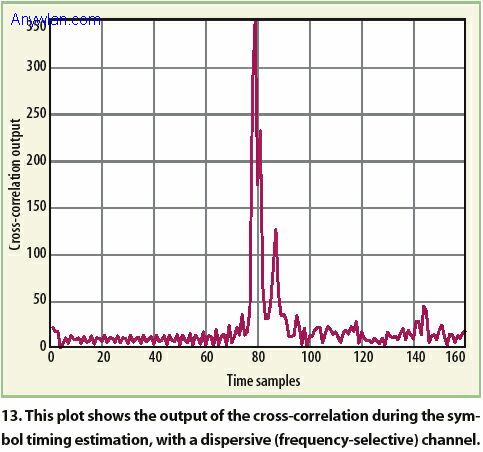
同步定时指找出每个OFDM符号头的准确定时瞬间。除非已知正确的定时,否则在对其样本作FFT运算时,接收机就不能正确去掉正好在符号和分离的单个符号的定时瞬间的循环前导。同步定时算法基本上要对通过分组检测算法得到的粗符号定时进行细调,精细符号定时使用短训练序列计算得到,还要计算接收信号和已知参考信号间的互相关。在这种情况下,当互相关最大时,我们就可得到最合适的定时位置。不过,由于多径分量,有可能观察到多个峰,还有,最大峰不一定对应第一个多径分量,因此,需要对多径信道进行额外的符号定时细调。我们使用联合信道估计和符号定时估计的方法对符号定时估计进行细调。 图12给出了接收信号与已知参考信号间的互相关。最大值出现处的峰清晰显示出扁平衰落信道(有一个多径分量)正确的定时点。不过,当信道是选择性衰落时,可观察到多个峰。图13给出了频率选择性信道的互相关器输出。
分组末端检测与分组抽取模块用来检测分组的末端,这对于测量用途特别重要(对于常规接收机不是主要部分)。如果FCH信息内容得不到,或者一些关于RF突发的副信息作为输入给出,我们就可避开分组末端检测计算,否则,需要打开这项功能以便我们不会对接收信号的噪声部分进行译码和测量。 算法利用了RF突发前后的间隙来确定RF突发的结束。在打开RF突发之前,只有噪声的间隙时间被用来计算噪声功率。因为已检测出RF的开始,我们还可计算RF突发(注意到我们使用前导之后的该数据来实现此目的,即跳过前导)起始点之后的信号加噪声总功率。较短时间间隔足以用来计算信号加噪声功率,使用这两个计算出的数据片,有可能开发出寻找分组末端的判决标准。 第一步是利用噪声功率与信号功率来确定信号-干扰功率比(SNR),噪声功率是在分组开始前测量得到,信号功率则在分组开始后得到(假定信号功率远大于噪声功率,则噪声功率在分组传输期间可忽略不计)。信干比计算如下:
这里, W是样本窗(在我们的例子中为一个OFDM符号长度的样点数,即256)。 对所有接收样本,SNR在样本的非重叠数据块上被监测,(为了降低计算复杂度,使用了非重叠数据块,不过仍有可能使用滑动加窗)。于是,将每个数据块的SNR值同上面给出的SNR值作比较,当SNR低于门限值后,就宣告分组结束。门限选择是设计关键。 信道估计是许多相干无线通信接收机的主要功能部分,可以从文献中获得很多先进的信道估计技术。这里应用了一个非常简单的信道估计器。在工作中,信道被假定为在数据分组传输期间几乎恒定,前文对此已有说明。一种简单的最小均方(LS)信道估计器被用于信道频率估计,该估计器使用一滑动窗进行噪声平均。LS估计器给出如下:
这里,Xpilot是前导中已知的载波符号。 带有两个相同重复性数据块的前导头符号被用于进行信道估计。正如前面所提及的,在训练符号中,导频载波(即已知导频载波的总数是100)之后的一个载波被跳过(空载波),因此,有必要进行内插以寻找空载波中的信道参数。在所提出接收机中使用了一种简单线性内插技术。在内插之后,应用了滑动窗滤波来减少估计中噪声的影响。注意到滑动窗的大小需要仔细选择,如果窗口长度过大,对于高色散信道,信道估计效果就不好,反之,如果窗口尺寸偏小,就无法达到最佳的噪声抑制效果。 在数据传输期间,应用了信道均衡来去除来自接收样本的信道影响。信道均衡如下进行:
在导频跟踪中,要完成公共相位估计、样本定时估计以及公共增益跟踪。对于使用八个导频符号的每个OFDM帧,接收信号的相位旋转被估计出来并被校正。通过把接收导频乘以共轭参考导频和计算结果相位,就可以找出发送和接收符号间的平均相位差。一旦估计出相位旋转,就容易进行校正。公共增益误差也采用类似上面比较发送和接收符号间增益差的方式被估计出来。样点定时误差略为棘手,需要对时间和频率上相位变化均有所考虑。在我们的接收机中,我们使用了时间和频率相位差来计算样本定时误差。 为了正确检测发送符号,接收机必须知晓发射机使用何种调制类型,该信息包括在FCH内容之中;不过,如果得不到FCH或者接收机不能对其译码,就需要盲调制检测。盲调制检测传统上有两种途径:即模式识别和判决理论方法。在统计模式识别方法中,已提出一些公认的模式识别算法,如模糊(Fuzzy)C方法聚类,如果在样本数相对多的情况下进行判决,这些算法经验证工作得很好。 盲调制检测的目标是使用尽可能少的接收样本来确定用于传递信息的调制方式,已接收的含噪声信号样本提供的唯一经验数据是跟所有可能调制方案中最为合理的星座点的距离,换言之,给定含噪声的信号样本,可能有M个错误,这里M是所用的调制方案种类数。这样,检测目标就是利用这些经验数据或者错误,对所用调制类型作出统计推断。 有一个盲调制检测的技术是基于判决理论方法,计算接收信号样本与各种可能调制方案的最合理星座点之间的平均欧氏距离(mean Euclidean distance)。不同假设条件下的平均欧氏距离可如下计算:
这里,Y是接收的信号样本,/Y是假定的接收样本,m是调制指数,K是用于平均的样点数。 该方法需最小化欧氏距离e,并被选择用来解调(24式)。不过,不管实际使用了哪种调制,在高阶调制方案中总存在一偏离,其原因在于对于可产生更低错误的更高阶调制方案,会出现更接近合理的星座点, 为了补偿偏离,文献提出了信息理论方法,如Akaike信息准则(AIC)和贝叶斯信息准则(BIC)。作者在提出的接收机中也采用了这类技术。基于穷举测量,作者开发了自己的信息准则。类似于上面的方法,该方法包括首先计算对每种假设调制的误差项,然后引入一校正项:
这里,β为一常数,当前的例子中取值0.9,Mm是第m种调制假设的星座图调制进制。 最终检测结果是是/em达到最小。 在定义突发方式(类似用于调制和编码的突发长度)的传输参数包含在FCH中时,FCH译码非常有用。具备FCH译码能力时,可以获得更加准确的测试性能。FCH包含下行链路帧前导(DLFP),它明确了调制类型和与FCH之后一个或多个下行链路突发相关的符号数。紧接FCH之后第一个下行链路突发采用的调制和编码在RateID中明确。RateID为一个4b编码。下行链路间隔使用码(DIUC)也是一类似RateID的4比特编码,用来辨别该下行链路中其它突发方式。DLFP还包括一个8比特的头校验序列(HCS),用来检测错误。 FCH 译码需要对接收信号样本解调、去随机、译码和去交织。此外,还需要CRC(循环冗余校验)来检查已编码比特流正确与否,换句话说,为了能对FCH的内容译码,需要完整的基于标准的接收机。所提出接收机内建了FCH译码功能。一旦FCH内容被译码出来,就需要被分散到其相关区域。IEEE 802.16-2004标准提供了对FCH译码内容的描述。 本网站的技术文章《WiMAX收发机的关键测量参数及测量技巧》将讨论一些测量方法,这些测量方法可以用本文构建的实验性WiMAX测试接收机来完成。 作者:Huseyin Arslan,Email: arslan@eng.usf.edu,美国南佛罗里达大学 Daljeet Singh,Anritsu公司 |
Archiver | 手机版 | 无线门户 ( 粤ICP备11076993号|粤公网安备44010602008359号 ) |网站地图
GMT+8, 2026-5-18 13:25
Powered by Discuz!
© 2003-2024 广州威思信息科技有限公司